
How does session-based recommendation engine work? WSKNN algorithm overview
Session-based recommendation engine in Python
part 3
Introduction
WSKNN package is a session-based recommender system, and its core is the VSKNN architecture (Vector Multiplication Session-based k-NN algorithm). Do you wonder why “V” had been changed to “W” along the way? To understand it, you should understand how the VSKNN algorithm works.
This chapter is theoretical, but don’t be discouraged. When you understand the model architecture, you will make better decisions about parameter settings. With this knowledge, you may set parameters to increase Key Performance Indicators (not only theoretical metrics).
Layers
The WSKNN model has four layers.
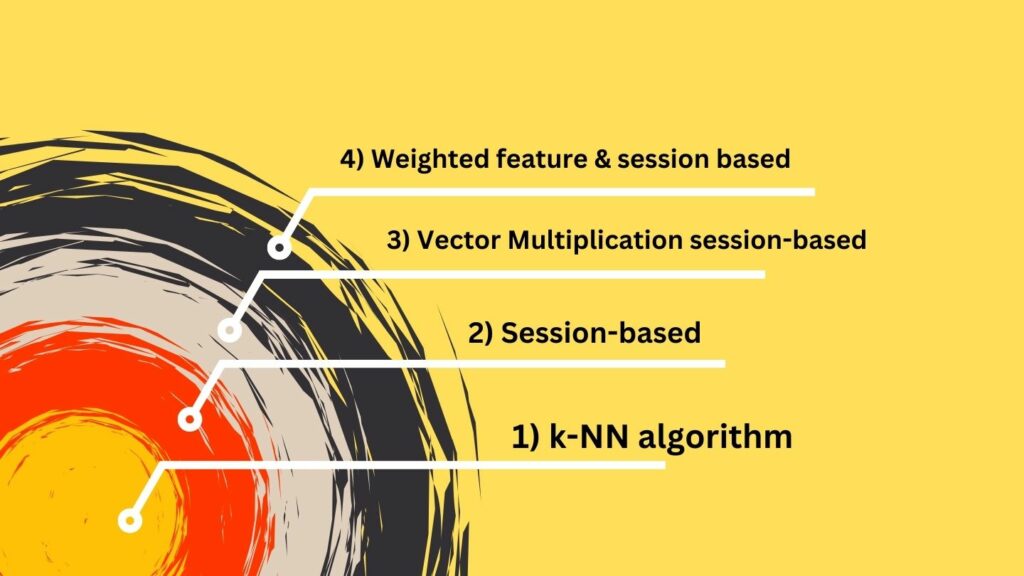
- The innermost layer is the k-Nearest Neighbors (k-NN) algorithm
- The middle layer is session-based k-NN
- The next layer is weighted session-based k-NN
- The outermost layer is a weighted feature and session-based k-NN.
Let’s understand each layer, starting from the core algorithm.
K-NN Algorithm

Consider four users {A, B, C, D}. Every user has watched some movies, but we focus on user A. Which movie should be recommended for this person?
K-nearest neighbors algorithm can help with a recommendation. It checks how similar sequences are. We measure similarity in many ways. The simplest way is to count how many common movies are in each sequence and build a similarity matrix. Person B has watched two movies as person A (score 2), person C one movie, and person D four movies. After estimating their similarity, the algorithm will link person A to person D (and B). The closest neighbors are user A and user D – their sets of movies have the highest number of common elements.
Session-based k-NN
The previous example had four sessions, but we deal with millions of sequences in the real world. Let’s increase the number of example sessions in the image below.

Now, we have ten user-sessions. Each session has a different length, which makes data modeling harder (most machine learning models are trained on datasets with fixed shapes and sizes). Data scientists can trim long sessions, drop short sequences, or even populate short lists with dummy values. The downside of this approach is the unwanted data manipulation.
Fortunately, some algorithms work on varying-size sequences, and session-based k-NN is one of those.
In the session-based context, we focus on sessions instead of items. First, we build a possible neighbors map. The basic algorithm samples the potential neighbors of the user by checking if there are overlapping movies in sequences. If user A has watched Jurassic Park, and user B has watched many other movies, and Jurassic Park is one of these, then user B is a possible neighbor of user A. Possible neighbors’ set sizes might be small for massive datasets with hundreds of movies.
When we have possible neighbors, we do the same step as in the k-NN algorithm – we count overlapping items between users and build a similarity map between our users. We pick N-most similar neighbors from the similarity set, check what items they have, and return the most common of those as recommendations (with a limitation that we don’t recommend movies that user A has watched).
Vector Multiplication Session-based k-NN
Each session is a sequence of interactions between the user and the movies. The period between actions doesn’t matter as it could with a time series where intervals must be fixed. However, there still are reasons to think about the time frames of those sequences, and the most important is practical. Customers’ preferences change over time and are modulated by seasonal patterns and anomalies. Look into Google trends data for a flowerpot in Poland (flowerpot in Polish is “doniczka”). Do you see what happened after COVID?
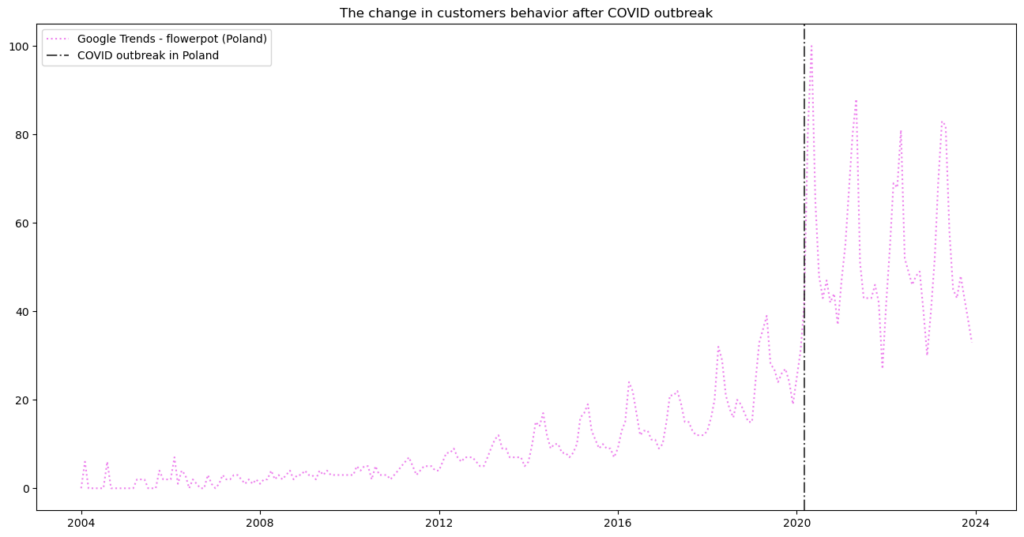
Customers’ behavior changed significantly during the first lockdown! But it was an anomaly. We see seasonal patterns, too. Changes can be abrupt, slow, cyclical, and in most cases – inevitable.
With this in mind, we can look at sequential (session-based) data as an opportunity. We might find patterns in how users’ taste for movies evolves when comparing other people with their sequences. The newest movies in a cinema should gain more weight for recommendation due to the cultural trends and a high chance that users have seen older titles.
Session-based k-NN weighting is linear, but we can introduce the decay function when we include time in our modeling. In a sequence, it will give higher weights for the most recent movies (items).
The image above shows the concept of time-dependent weighting: the most recent movies in a sequence gain additional weight. Thus, the final recommendations will definitely differ from those given by a simple session-based k-NN.
Weighted feature & session-based k-NN
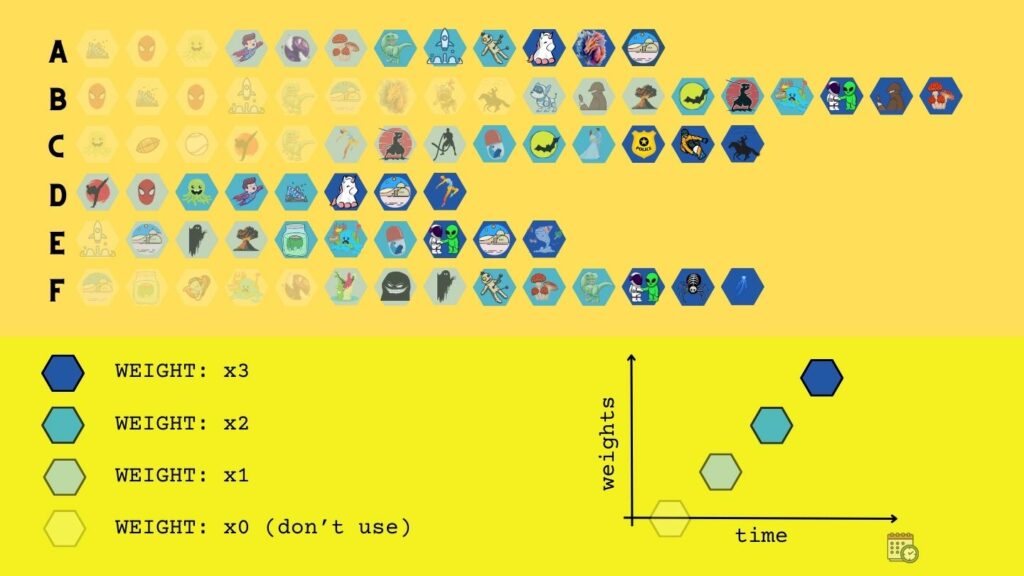
As you may have noticed, the k-NN algorithm is very flexible. And it can be further customized. Let’s assume that you want to promote a specific genre. You may assign additional weight to sci-fi movies and, at the same time lower weights of documentary series. Or you can promote a particular movie from a database or set a custom weight to every movie. The WSKNN algorithm does that.
It was designed for the online shop sessions. Each session consists of repeating customer-actions: view, click, add to cart, remove from cart, scroll, purchase. For retailers, the most important is purchase. Thus, we should emphasize it with higher weight for purchased events than for the viewed items. Or otherwise, if a seller wants to experiment with recommendations and try to convince customers to check things that are not purchased.
Our role is to find a weighting factor and pass it with the input. The algorithm will use it to pick the most similar sessions and most similar items from a database. First, it will weight the recommendations by a function of time. Then, it will weight them again by custom weighting factors.

In the image above, we have one example of a business-driven weighting. We decided that sports movies should be recommended first because our analysis shows that users generally love those movies but don’t know the titles. Super-hero stories shouldn’t be recommended so frequently because they are widely known, and spending additional resources for their marketing is wasteful.
A word of advice: feature-based weighting will probably damage the model’s evaluation metrics because they rely on static historical data [see previous article]. Weighting by external factors is a step forward from a static model – now you interfere with customers’ decisions by exposing a group of products. External weighting factors should be used cautiously, and their outcomes must be measured using A/B tests and business Key Performance Indicators.
Summary
In this article, we learned how a session-based recommendation system works internally, and you have a high-level technical overview of the WSKNN algorithm. Using this knowledge, we can dive deeper into the parameter space of the WSKNN algorithm.





