
The performance of session-based recommender should be evaluated with business metrics
We should judge a model’s performance by its ability to solve our problems – specifically, by the Key Performance Indicators, such as quarterly revenue. Suppose we change our focus from theoretical metrics to business indicators. In that case, we may avoid implementing any ML solution, which is good – we want our system to be as simple as possible. Moreover, KPI might be correlated with theoretical metrics but there is a chance that the correlation is weak and the optimal theoretical model won’t work well in production…
Let’s start with the example without Machine Learning. We can recommend products based on the user’s action history and use viewed items as recommendations, sorting those with time from the newest to the oldest items. Recommender engine, in this case, is a set of SQL queries. No MLOps, no Python, just a database and a few simple operations – that’s all we need. How do we measure the performance? We cannot use precision, recall, or F1 score. There’s no model. We should level up from Data Science metrics into business indicators and ask ourselves: what do we want to achieve? We want to increase profits. Therefore, we must measure if our conditional model positively influences quarterly profits. How do we measure it? There is a tool known from the UI/UX design. It’s A/B testing. How does it work? Look at the schema below:
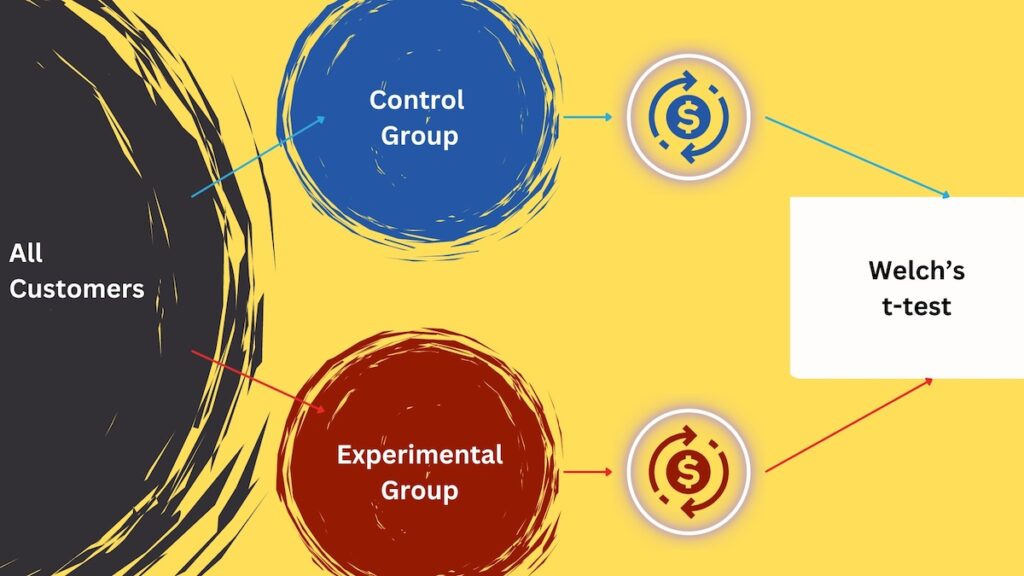
We split the customer base into two parts: the control and the experimental groups. The experimental group is sampled randomly; it could consist of 1% or 10% of the clients. The control group receives communication without recommendations. The experimental group gets recommendations from our system. We use transactions from the control and experimental groups after one week or month. First, we check if the experimental group’s average transaction value increased. Sure, it has! Now, we check if this change is statistically significant. We use Welch’s t-test (implemented in almost every popular programming language) to check if the difference between the groups’ mean is significant.
The core requirement in this scenario is to maximize profits. Thus, we compare earnings with and without recommendations. We should do it at regular intervals, not only once, because the model may worsen with time, or our assumptions about the recommender will become invalid due to seasonal patterns or unexpected trend changes. And business may reconsider the baseline requirements. Hypothetical scenarios: mean transaction value increases, but the recommender shows only a small group of products, and customers buy items only from this group. We need more physical storage space for other items; we pay for the warehousing more, and finally, our net annual profits go down. Moreover, a customer buying products from one category – for example, printing materials – will never know that our shop has smartwatches because our recommendation engine recommends printing materials only for this person. We want to tell customers about different product categories in our stock, but the recommendation engine creates a walled space (bubble) around one product category. (Doesn’t it remind you something? Isn’t it how social media recommender work? Their profit maximization depends on rules different from online shopping, and enclosed spaces might be desirable here).
What can we do with our hypothetical problems? The answer is simple: ML or conditional models should be optimized with business metrics in mind, and we tweak the system with those indicators in mind. Those KPIs may correlate with theoretical metrics, but there might be times when KPI performance is not easily transferred to simple tuning metrics. A/B tests are our first-choice tool in this context. When we establish the MLOps pipeline and start measuring business outcomes with A/B testing, we can adjust our algorithms and decide which theoretical metrics are closely related to KPIs. For starters, we have two choices for how the engine might work.
- AMPLIFICATION: The amplifier of the customer’s taste, past transactions, and product/post/service categories preferred by the user. We want customers to buy more from the categories they are interested in.
- EXPLORATION: We want to show customers new categories and items that relate to their taste or are entirely outside it.
Which mode is better? The first mode will probably increase short-term profits (weekly, monthly), but users might notice that we recommend products they know, which may anger some people. The second mode might increase earnings in the long run, or we may apply it to the new users only to show them our item base. For social media, the exploration mode prevents tribalism and makes invisible bubbles less stable; it creates a less toxic environment.
How can we amplify the current behavior? Tune models to maximize their precision. How do we set the discovering mode? Maximize recall and put additional weights for items outside the most frequent categories in user’s sessions. Then, we must establish clear business metrics to know if the models work as expected. For the first model, it could be the frequency of transactions or the time between transactions. The second model could be measured by a count of distinct categories in the customer’s basket. And for both, we can measure revenue in a short and long time window.
Let’s wrap up what we have established so far. Business metrics defines the model performance. Recommendations engines have two main modes of work: amplification and exploration, and both can be measured with revenue changes or specific KPIs. The next takeaway from the article is that recommendation engines rarely work as a single process enclosed in one machine learning algorithm (for example, Matrix Factorization). The data preparation step has a massive impact on the model’s performance. We filter data, so we must find answers to multiple questions. How many days back should we include users’ actions and transactions in the model? How many user actions are required for modeling? Is there a minimal transaction threshold, or should there be a transaction? Does the user session end with the transaction, or is it just another action in a session defined only by time frame? Should we include item categories such as postal delivery in our sessions? Can we merge recommendation output with external model information? The list is not closed, and it may contain a different set of questions for different e-commerce settings.
We might alter the system’s amplification/exploration capabilities with data preprocessing. We can cut off items that are rarely bought, thus putting more emphasis on amplification. Alternatively, we can remove overrepresented items and force the model into the exploration mode. However, we must remember that every change in the data preprocessing phase will lead to different business outcomes. That way, if we want to filter more input data, we should perform A/B tests and check whether business KPIs are better.
With this knowledge, you can create and maintain a session-based recommendation engine. Previous articles show you how a session-based recommendation engine works, how to develop it with Python and the wsknn package, and which parameters you can tune to get the expected results. This article shows the problem differently and will help you build and MAINTAIN your recommender! If you feel something should be described better, don’t hesitate to comment!
Previous posts





