
Toolbox: drop duplicated geometries from GeoDataFrame in Python – 2024 update
You came here to get the code for dropping duplicated geometries in GeoPandas GeoDataFrame, so let’s start with the code. If you are interested in a detailed explanation, you can read the text below the code.
def norm_drop_geometries(geoseries: gpd.GeoSeries):
"""
Function normalizes geometry in a geoseries, and then drops repeating records.
INPUT
:param geoseries: (gpd.GeoSeries)
OUTPUT:
:returns: (gpd.Geoseries)
"""
normalized = geoseries.normalize()
deduplicated = normalized.drop_duplicates()
return deduplicated
The article is an updated version of the note from 2021. Many thanks to Freddy Fingers for pointing out the normalize() method from GeoPandas.
Introduction
In 2021, I’ve shared an article on how to deduplicate complex geometries in GeoDataFrame. The biggest obstacle with this procedure was the ordering of points in Polygons. You can have two geometries that are the same but start from a different point, and the drop_duplicates() method won’t work. To overcome this problem, I shared this function:
def drop_duplicated_geometries(geoseries: gpd.GeoSeries):
"""
Function drops duplicated geometries from a geoseries. It works as follow:
1. Take record from the dataset. Check it's index against list of indexes-to-skip.
If it's not there then move to the next step.
2. Store record's index in the list of processed indexes (to re-create geoseries without duplicates)
and in the list of indexes-to-skip.
3. Compare this record to all other records. If any of them is a duplicate then store its index in
the indexes-to-skip.
4. If all records are checked then re-create dataframe without duplicates based on the list
of processed indexes.
INPUT:
:param geoseries: (gpd.GeoSeries)
OUTPUT:
:returns: (gpd.Geoseries)
"""
indexes_to_skip = []
processed_indexes = []
for index, geom in geoseries.items():
if index not in indexes_to_skip:
processed_indexes.append(index)
indexes_to_skip.append(index)
for other_index, other_geom in geoseries.items():
if other_index in indexes_to_skip:
pass
else:
if geom.equals(other_geom):
indexes_to_skip.append(other_index)
else:
pass
output_gs = geoseries[processed_indexes].copy()
return output_gs
Three years passed, and I got a comment from Freddy Fingers about a different method – first, normalizing geometries in GeoSeries and then using the drop_duplicates() method. The only problem was benchmarking. Is this other method faster? Short answer: It is.
Normalize and drop
Usually, internal methods provided by package maintainers are better than ad hoc solutions. Thus, if we can, we should use those. The other important practice is benchmarking. To be sure that the function based on GeoPandas normalize() is faster than the function based on the Shapely equals() method, I’ve performed multiple tests on a dataset with a growing size. The full test suite is available in this notebook: HERE
Going straight to the results, here is the plot of processing time for each function:
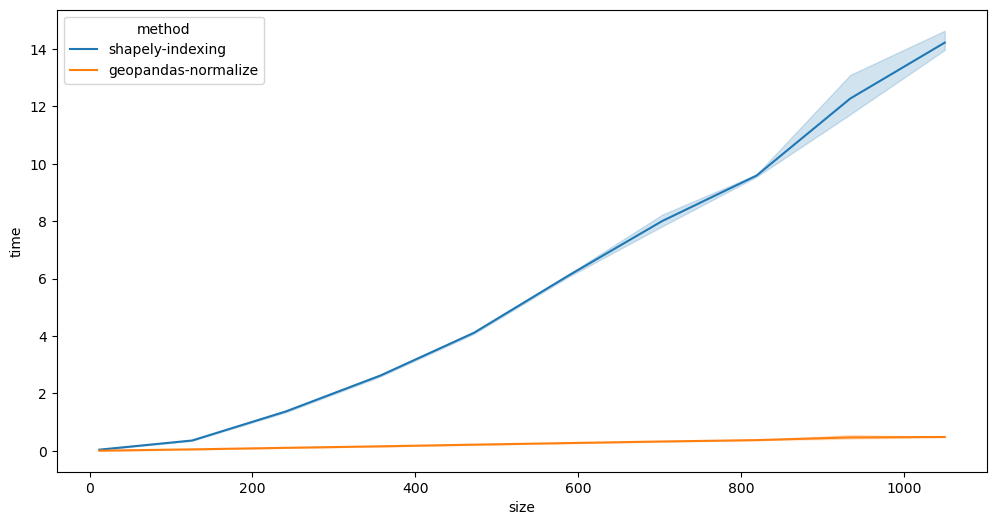
As you can see, the processing time of a custom function is much slower, and the difference between times sharply increases with a dataset size. Code readability is the next issue.
We started a note with a valid code, and we will end it with the same code. Remember to update your projects if you are using the old function!
def norm_drop_geometries(geoseries: gpd.GeoSeries):
"""
Function normalizes geometry in a geoseries, and then drops repeating records.
INPUT
:param geoseries: (gpd.GeoSeries)
OUTPUT:
:returns: (gpd.Geoseries)
"""
normalized = geoseries.normalize()
deduplicated = normalized.drop_duplicates()
return deduplicated




