
Toolbox: Drop Duplicated Geometries from GeoDataFrame
NOTE
The updated version of this post with a better solution is available here.
Old version (2021) of the article
Did you ever encounter any problems with duplicated geometries in your dataset? I do! The duplicate may create hard-to-debug errors in our analysis. That’s why it is crucial to track copies and exclude them from our research. Data presented in the table below is not so uncommon in GIS applications as one should expect:
| ID | x | y | value |
| 1 | 10.78 | 52.11 | 10 |
| 2 | 9.11 | 51.05 | 5 |
| 3 | 9.11 | 51.05 | 12 |
| 4 | 7.42 | 52.98 | 3 |
Look at the point 2 and 3 – their coordinates are the same but values are different. Are both the same point? Are those the various locations, and we made a mistake with rounding up the floating points? Sometimes there’s no way to answer those questions, and the only option is to remove duplicated geometries.
There is drop_duplicates() method from Pandas package in Python, which we could potentially use to remove duplicates:
drop_duplicates() method from the Pandas
import geopandas as gpd
gdf = gpd.read_file('geoseries.shp') # We assume that the geometry column is a column with geometry
cleaned = gdf.drop_duplicates('geometry')
This method should work fine for Point type geometry. The problem arises when we compare the Line and Polygon types of geometry. Look into an example:
from shapely.geometry import Polygon polygon_a = Polygon([(0, 1), (2, 3), (2, 6), (0, 1)]) polygon_b = Polygon([(2, 3), (2, 6), (0, 1), (2, 3)]) gs = gpd.GeoSeries(data=[polygon_a, polygon_b]) print(len(gs.drop_duplicates()))
2
What went wrong? Both geometries are the same, but for Pandas, they are different. The order of points is relevant here! That’s why we should be very cautious with the methods designed for the non-spatial datasets. So how can we drop duplicates? There’s a method from the shapely package named equals() which we can use to test if geometries are the same. If so, then we can drop unwanted rows from our GeoDataFrame.
Drop duplicated geometries with shapely
The function works as follow:
- Take record from the dataset. Check it’s index against list of indexes-to-skip. If it’s not there then move to the next step.
- Store record’s index in the list of processed indexes (to re-create geoseries without duplicates) and in the list of indexes-to-skip.
- Compare this record to all other records. If any of them is a duplicate then store its index in the indexes-to-skip.
- If all records are checked then re-create dataframe without duplicates based on the list of processed indexes.
def drop_duplicated_geometries(geoseries: gpd.GeoSeries):
"""
Function drops duplicated geometries from a geoseries. It works as follow:
1. Take record from the dataset. Check it's index against list of indexes-to-skip.
If it's not there then move to the next step.
2. Store record's index in the list of processed indexes (to re-create geoseries without duplicates)
and in the list of indexes-to-skip.
3. Compare this record to all other records. If any of them is a duplicate then store its index in
the indexes-to-skip.
4. If all records are checked then re-create dataframe without duplicates based on the list
of processed indexes.
INPUT:
:param geoseries: (gpd.GeoSeries)
OUTPUT:
:returns: (gpd.Geoseries)
"""
indexes_to_skip = []
processed_indexes = []
for index, geom in geoseries.items():
if index not in indexes_to_skip:
processed_indexes.append(index)
indexes_to_skip.append(index)
for other_index, other_geom in geoseries.items():
if other_index in indexes_to_skip:
pass
else:
if geom.equals(other_geom):
indexes_to_skip.append(other_index)
else:
pass
output_gs = geoseries[processed_indexes].copy()
return output_gs
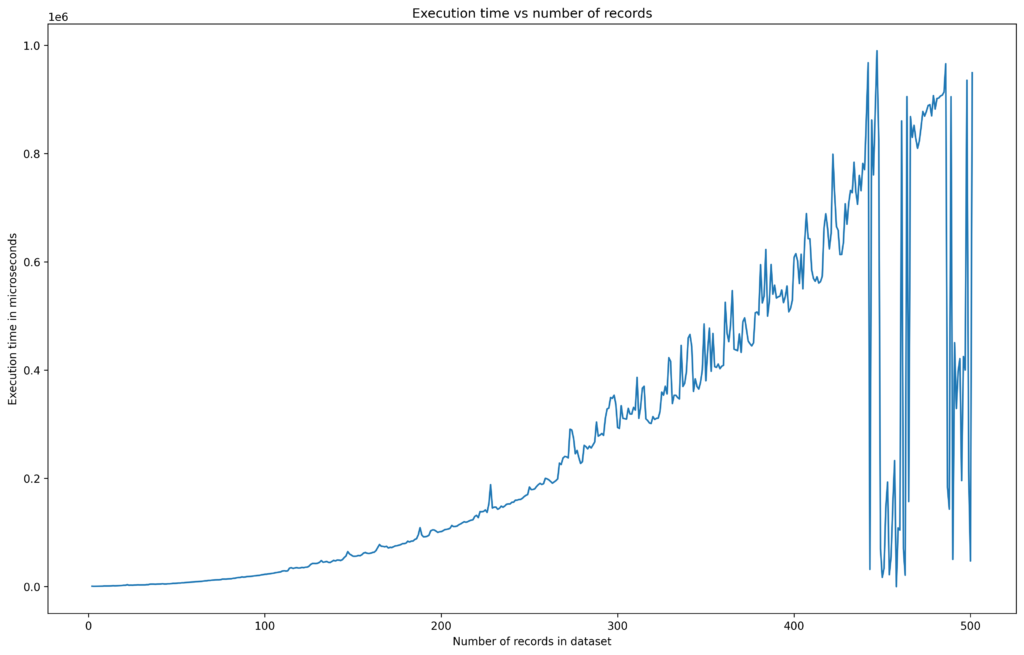
This function is much safer than the .drop_duplicates() method of Pandas. The only problem is its complexity: in the worst-case scenario, it is O(n^2), and in most cases, it is O(n log n). The sample curve of execution time vs. a number of records is present below:






Thanks this is very helpful.
How does this compare to using the geodataframe normalize() function and then drop_duplicates()?
This is a really good question! I will test it and let you know.
Freddy Fingers thank you – you were right! First normalize then drop duplicates, here you have the benchmarking: https://ml-gis-service.com/index.php/2024/11/05/toolbox-drop-duplicated-geometries-from-geodataframe-in-python-2024-update/