Data Engineering: Nested Data Structures in Python. How to Prevent Data from Overwriting Itself
Working as a data engineer can be tricky, and traps are everywhere. We can avoid most of them if we use high-level packages (like pandas), but with costs:
- the
DataFramehas greater complexity than core Python data structures, - a processing time is longer than with basic structures,
- our engineering and DevOps team will have to manage additional dependencies.
It’s hard to estimate how often we need those high-level packages. Twenty percent? Ten percent? In my opinion, pandas shouldn’t be a production tool. Don’t get me wrong, pandas is a must-have for rapid prototyping of data engineering platforms, but its parsing performance is relatively poor, especially for data that deviates from a classic table view. Python’s basic data structures: set, list, or dict are enough to quickly transform large amounts of data. The usage of simple data structures has its costs. The wrong code will run, but the results will be unexpectedly bad! We will look into one case when using nested dictionaries with lists can be dangerous.
List and dictionary behavior in Python
Python lists and dictionaries are specific objects. If we assign those to the new variable, we don’t create a new entity in memory but only a new pointer to the existing object. This is a convenient feature, lists and dictionaries are usually very big, and it is not reliable to copy them every time and risk a memory overflow. But it has a drawback – the risk of changing the object structure even if we don’t want to do it. Let’s investigate simplified examples.
List:
a = [] b = a c = a b.append(3) c.append(10) print(a, id(a)) print(b, id(b)) print(c, id(c))
[3, 10] 4444656768 [3, 10] 4444656768 [3, 10] 4444656768
Dictionary:
a = {}
b = a
c = a
b['0'] = 0
c['1'] = 1
print(a, id(a))
print(b, id(b))
print(c, id(c))
{'0': 0, '1': 1} 4443302208
{'0': 0, '1': 1} 4443302208
{'0': 0, '1': 1} 4443302208
We modified variable b and variable c, but all of them were transformed. It isn’t a surprise. Those variables are just different names for the same list and the same dictionary! As we said before, this could be desirable behavior, and in most cases, it is. But there are situations when we don’t want our objects to behave this way.
E-commerce session weighting example
Let’s consider an example from an e-commerce shop. We have a set of different sessions, and each session is a sequence of a fixed length. The series is created from three events: click, view, and scroll. They can be in any order and can repeat themselves. Here are examples for a session of length 3:
- view, view, scroll
- click, scroll, view
- click, click, click
- … And all possible permutations of this triple of values.
Sequences in sessions may repeat themselves, and they are not unique.
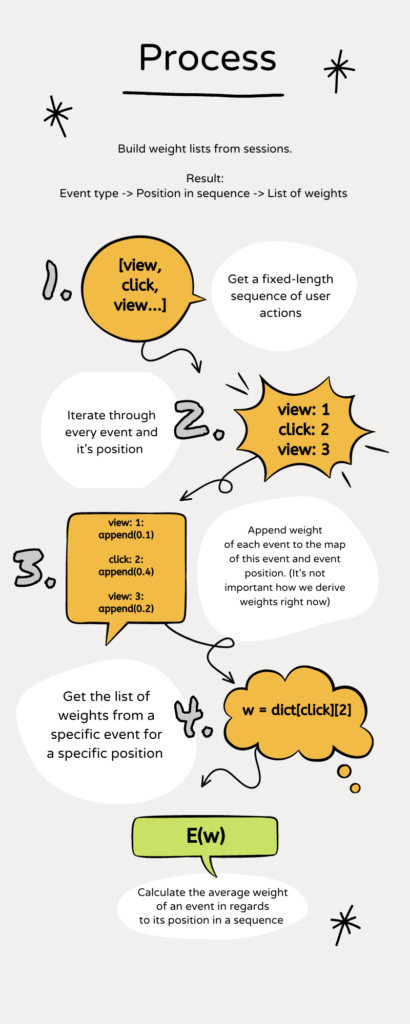
For each event, we have a subset of weights. We may think of those weights as a probability that this event will occur at a specific place in a sequence. (The stated problem directly relates to Markov Chain analysis and the attribution weighting in e-commerce). From the engineering perspective, we have a few steps to perform. The process is presented in the figure near a text. Look into it and then come back to the text.
Our transformation is in a loop. We take a fixed-length sequence of events (session) and parse it (step 1). First, we parse each event in a series. The position of the event is important (step 2). Our role is to design a simple data structure that stores the weights of the events, but with regards to the event position in a sequence. The example is presented in step 3: view event on the first position receives some weight. We have three pieces of information here. Two are constant, and one is dynamic: (const event name, const event position, dynamic event weight). Our analytics team is interested only in the weights, and there could be multiple weights per event at a specific position. The natural way of describing this dependency is a 2-level dictionary pointing to a list with weights: dictionary[event name][event position] = [weights, ].
In step 4, we update the list with weights for the event/position pair. And here is the tricky part. If we are not careful, we can update only a single dictionary with positions for each key from the dictionary with the event name!
Let’s code the whole process. In the first iteration, we will create a wrong dictionary structure and observe what happens if we forget about Python’s nasty properties of pointers to lists and dictionaries.
weights = {
'view': [0.2, 0.4, 0.4],
'click': [0.7, 0.1, 0.2],
'scroll': [0.1, 0.75, 0.15]
}
user_actions = list(
weights.keys()
)
First, we create weights array. Each event can take one weight from a list of weights. In real scenarios, this list is much longer and depends on the last event, but for simplicity, we randomly choose one weight from the list. With this array, we can prepare our data structure. Additionally, we have created a list of all possible user actions user_actions. The set of possible actions will be the first level in the dictionary. A next level is a nested dictionary with positions that points to lists with weights.
indexes_range = [1, 2, 3]
index_dict = {}
for idx in indexes_range:
index_dict[idx] = []
print(index_dict)
{1: [], 2: [], 3: []}
We have everything to create the weights aggregation container. And we are going to do it – incorrectly. Be careful! The following code listing is wrong, and we will prove it!
session_weights = {}
for u_action in user_actions:
session_weights[u_action] = index_dict
print(session_weights)
{
'view': {1: [], 2: [], 3: []},
'click': {1: [], 2: [], 3: []},
'scroll': {1: [], 2: [], 3: []}
}
Everything seems okay, but in reality, data will be processed wrongly. Let’s create sample data to test it.
import random
# Generate input data
generated_sessions = []
for _ in range(0, 1000):
# Create session of length N from random user actions
session = []
for _ in range(0, len(indexes_range)):
event = random.choice(user_actions)
session.append(event)
generated_sessions.append(session)
print(generated_sessions[0], [weights[x] for x in generated_sessions[0]])
['click', 'scroll', 'view'] [[0.7, 0.1, 0.2], [0.1, 0.75, 0.15], [0.2, 0.4, 0.4]]
We have 1000 sessions to update our dictionary (remember that the weight for each event is randomly chosen from a short list of possible weights). Thus, we will do it!
# Update dict with data
for g_session in generated_sessions:
for idx, event in enumerate(g_session):
iidx = idx + 1
event_val = random.choice(weights[event])
session_weights[event][iidx].append(event_val)
Ok, data is processed, and we are free to go. Or not? Let’s compare the last ten records from each event at the first position:
print(session_weights['click'][1][-10:]) print(session_weights['view'][1][-10:]) print(session_weights['scroll'][1][-10:])
[0.7, 0.2, 0.4, 0.4, 0.4, 0.2, 0.2, 0.2, 0.4, 0.1] [0.7, 0.2, 0.4, 0.4, 0.4, 0.2, 0.2, 0.2, 0.4, 0.1] [0.7, 0.2, 0.4, 0.4, 0.4, 0.2, 0.2, 0.2, 0.4, 0.1]
We got the same result every time! It is doubtful and even less probable if we compare those weights to possible outcomes.
- The click event can take weights: 0.7, 0.1, or 0.2, but in the list, we see 0.4!
- The view event can take weights: 0.2 or 0.4. But we see 0.1!
- The scroll event can take weights: 0.1, 0.75, 0.15. We see 0.4 and 0.2 that are unavailable; worse, we don’t see any occurrence of weights 0.15 or 0.75!
We should be very suspicious when we see results like that. If we dig deeper, we will uncover a painful truth:
print(session_weights['click'][2] == session_weights['scroll'][2]) print(id(session_weights['click']) == id(session_weights['view']))
True True
All results point to the same dictionary!
(There is a chance that we don’t check it, then our analysts will quickly uncover our mistake when they get statistics of each list. It will be equal for each event/position pair).
We forget that a new dictionary isn’t created in this loop; we repeatedly point to the same dictionary index_dict . Every time we update it for any user actions, we do it only for one object!
session_weights = {}
for u_action in user_actions:
session_weights[u_action] = index_dict
How should we define our data structure correctly?
There are a few solutions to this problem. We can use dict() or list() functions and make a copy of a dictionary or a list.
a = {'0': 0, '1': 1}
b = dict(a)
b[‘2’] = 22
print(a)
print(b)
{'0': 0, '1': 1}
{'0': 0, '1': 1, '2': 22}
Or, what is my preferred way, we can use the deepcopy() function. In this scenario, we can do it with any data type:
from copy import deepcopy
session_weights = {}
index_dict = {}
for idx in indexes_range:
index_dict[idx] = []
for u_action in user_actions:
session_weights[u_action] = deepcopy(index_dict)
# Update dict with data
for g_session in generated_sessions:
for idx, event in enumerate(g_session):
iidx = idx + 1
event_val = random.choice(weights[event])
session_weights[event][iidx].append(event_val)
print(session_weights['click'][1][-10:])
print(session_weights['view'][1][-10:])
[0.1, 0.1, 0.2, 0.7, 0.2, 0.1, 0.7, 0.7, 0.2, 0.2] [0.4, 0.2, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.2]
Voila! The parser works as expected!
Summary
The main takeaways from this article are:
- When we create a data structure and initialize it with another nested one, we must be sure that we don’t use the same nested object each time!
- Check object’s
id()in the unit tests, compare outputs, and be suspicious if some too-good-to-be-true patterns emerge from the data. - Use
copy.deepcopy()function to create new lists or dictionaries from existing ones.
Complete & working code listing
import random
from copy import deepcopy
# Object initialization
indexes_range = [1, 2, 3]
weights = {
'view': [0.2, 0.4, 0.4],
'click': [0.7, 0.1, 0.2],
'scroll': [0.1, 0.75, 0.15]
}
user_actions = list(
weights.keys()
)
session_weights = {}
index_dict = {}
for idx in indexes_range:
index_dict[idx] = []
for u_action in user_actions:
session_weights[u_action] = deepcopy(index_dict)
# Update dict with data
for g_session in generated_sessions:
for idx, event in enumerate(g_session):
iidx = idx + 1
event_val = random.choice(weights[event])
session_weights[event][iidx].append(event_val)